几道reverse基础题目wp
很简单,写的c语言脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <stdio.h>
#include <string.h>
int main () {
char Str1 [ 1000 ];
strcpy_s ( Str1 , sizeof ( Str1 ), "{34sy_r3v3rs3}" );
int i ;
for ( i = 0 ; i <= 665 ; ++ i )
{
if ( Str1 [ i ] == '3' )
Str1 [ i ] = 'e' ;
}
for ( i = 0 ; i <= 665 ; ++ i )
{
if ( Str1 [ i ] == '4' )
Str1 [ i ] = 'a' ;
}
printf ( "%s" , Str1 );
}
Tips:
1.使用strcpy函数要添加#include <string.h>函数头
2.在比较新的编译器里面,会对strcpy的安全问题报错,需对strcpy进行改进:
strcpy_s(str1,中间参数,str2);
中间参数的意义可以理解为:str2预计需要向str1占用多少空间
所以很显然中间参数的值的大小,必须大于等于str2的空间,但是小于等于str1空间(前提:str1>=str2)
通常情况下可以写为:
strcpy_s(str1,sizeof(str2),str2);
或者strcpy_s(str1,strlen(str2)+1,str2);
1
2
3
4
5
6
7
8
9
#include <stdio.h>
int main () {
char a [] = "d`vxbQd" ;
for ( int i = 0 ; i < 7 ; i ++ ) {
a [ i ] = a [ i ] ^ 2 ;
a [ i ] -- ;
}
printf ( "%s" , a );
}
把原本的python的脚本稍作修改,再跑一遍(xor加密)得到flag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import base64,urllib.parse
key = "HereIsFlagggg"
flag = "xxxxxxxxxxxxxxxxxxx"
s_box = list(range(256))
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
res = []
i = j = 0
for s in flag:
i = (i + 1) % 256
j = (j + s_box[i]) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
t = (s_box[i] + s_box[j]) % 256
k = s_box[t]
res.append(chr(ord(s) ^ k))
cipher = "".join(res)
crypt = (str(base64.b64encode(cipher.encode('utf-8')), 'utf-8'))
enc = str(base64.b64decode(crypt),'utf-8')
enc = urllib.parse.quote(enc)
print(enc)
# enc = %C2%A6n%C2%87Y%1Ag%3F%C2%A01.%C2%9C%C3%B7%C3%8A%02%C3%80%C2%92W%C3%8C%C3%BA
下面是修改之后的脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import urllib.parse
key = "HereIsFlagggg"
flag = "%C2%A6n%C2%87Y%1Ag%3F%C2%A01.%C2%9C%C3%B7%C3%8A%02%C3%80%C2%92W%C3%8C%C3%BA"
flag =urllib.parse.unquote(flag)
s_box = list(range(256))
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
res = []
i = j = 0
for s in flag:
i = (i + 1) % 256
j = (j + s_box[i]) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
t = (s_box[i] + s_box[j]) % 256
k = s_box[t]
res.append(chr(ord(s) ^ k))
cipher = "".join(res)
print(cipher)
//NSSCTF{REAL_EZ_RC4}
Tips :python脚本中最下边注释掉的enc就是正确的flag之后加密的,千万不要覆盖掉
反编译,很简单的代码审计,复制改程序的代码进行修改,逆向运算进行解密
下面是C语言写的脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main () {
char Str [] = "ylqq]aycqyp{" ;
int v7 = strlen ( Str );
for ( int i = 0 ; i < v7 ; ++ i )
{
if (( Str [ i ] <= 96 || Str [ i ] > 98 ) && ( Str [ i ] <= 64 || Str [ i ] > 66 ))
Str [ i ] += 2 ;
else
Str [ i ] -= 24 ;
}
printf ( "%s" , Str );
}
但输出的flag好像有点问题,确实怪
1
//{nss_c{es{r},{用a替换,得到{nss_caesar}为正确答案
非预期解:在十六进制数据对应的ASCII中发现了flag
[SWPUCTF 2021 新生赛]fakerandom
append()函数 ⽤于在列表末尾添加新的对象
random.getrandbits(k)
返回一个不大于K位的Python 整数(十进制),比如k=10,则结果是0~2^10之间的整数。
以下是算法逆向脚本:
1
2
3
4
5
6
7
8
9
10
11
12
import random
result = [201, 8, 198, 68, 131, 152, 186, 136, 13, 130, 190, 112, 251, 93, 212, 1, 31, 214, 116, 244]
random.seed(1)
l = []
for i in range(4):
l.append(random.getrandbits(8))
flag=[]
for i in range(len(l)):
random.seed(l[i])
for n in range(5):
flag.append(chr(result[i*5+n]^random.getrandbits(8)))
print(''.join(flag))
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
int main ()
{
srand ( 0x2766 );
printf ( "NSSCTF{" );
for ( int m = 0 ; m < 13 ; ++ m )
{
printf ( "%d" , rand () % 8 + 1 );
}
putchar ( '}' );
}
Tips :必须在Linux下运行才正确
非预期解:
预期解:
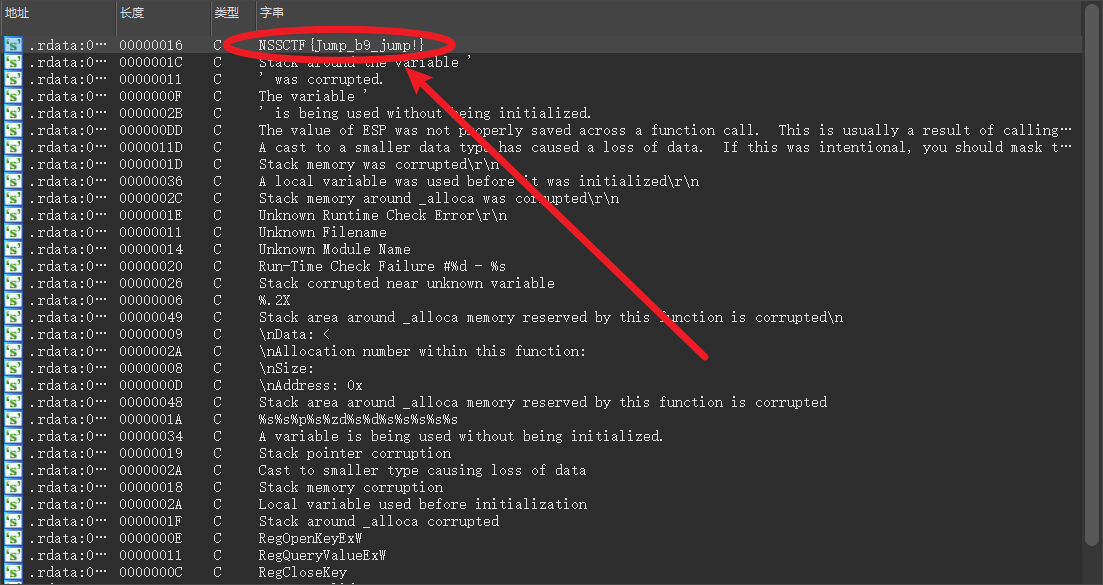
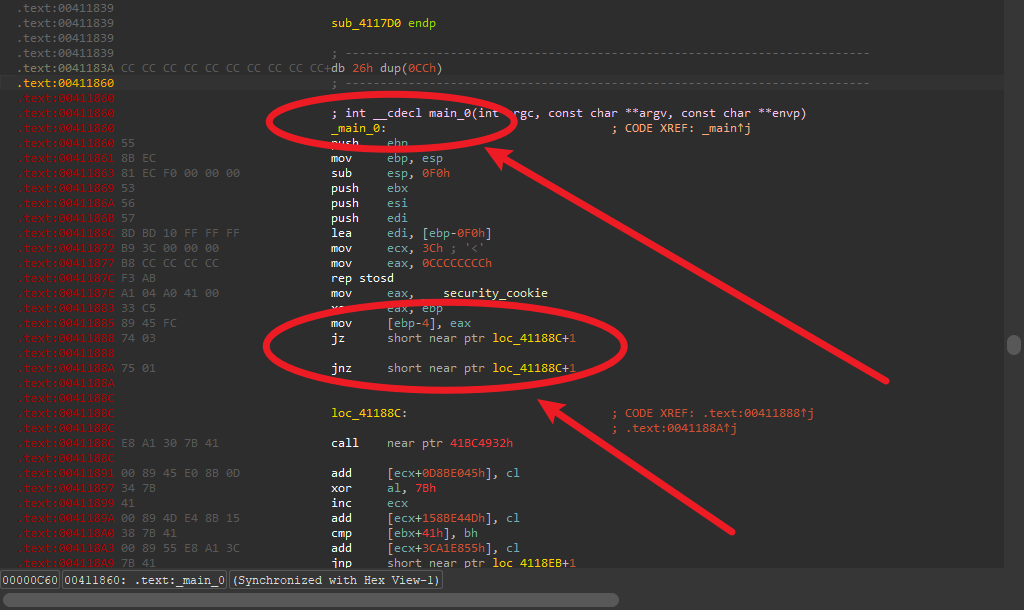
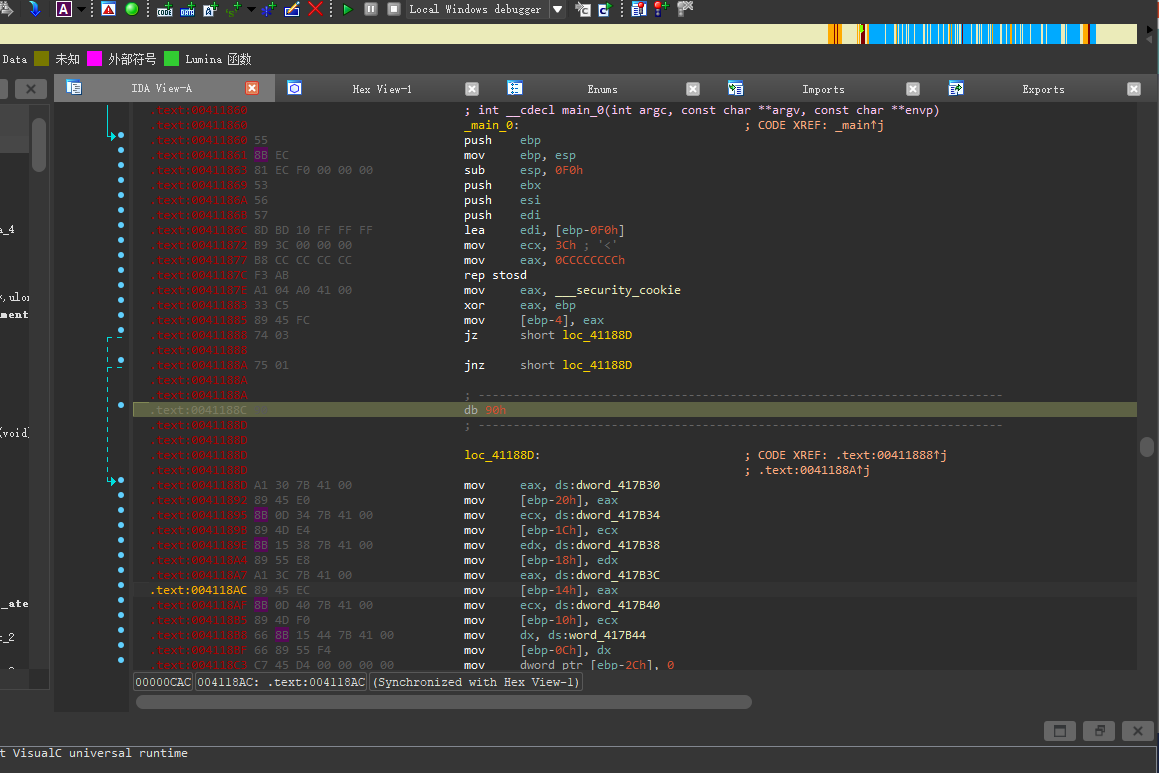
IDA32位,定位到main函数,发现花指令
快捷键D转换成数据
然后nop(90)
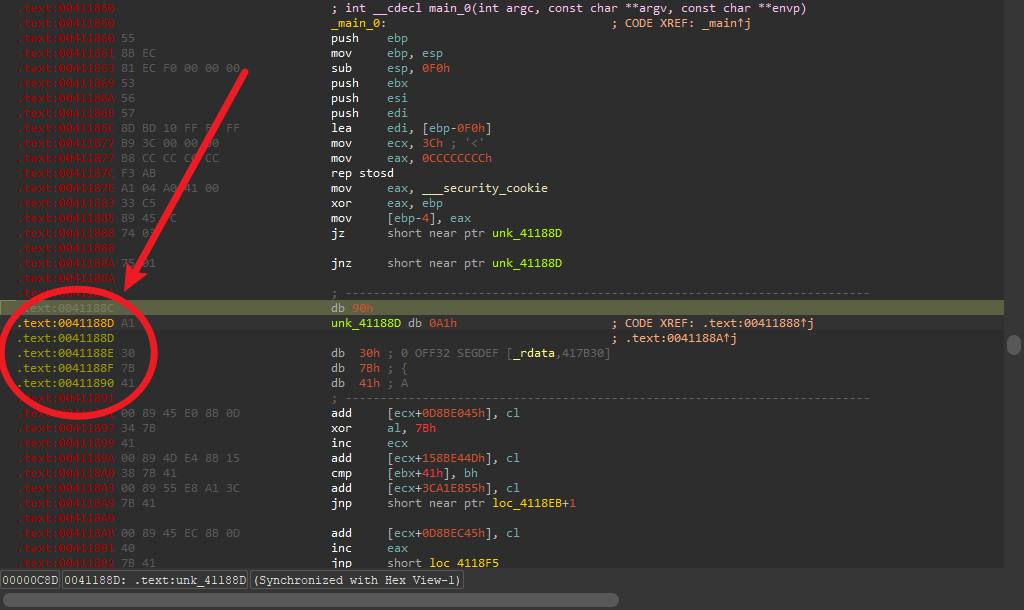
随后一路快捷键C将黄色代码转换成数据
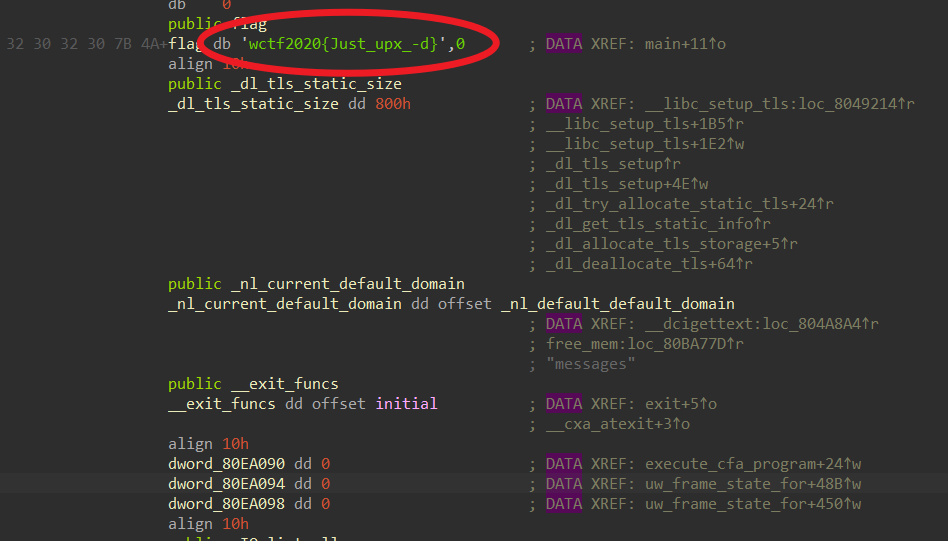
整理完成之后,创建函数,之后就可以进行F5反编译,得到flag
根据题目标签可知,UPX脱壳,可以用upx直接进行脱壳
https://github.com/upx/upx/releases
题目代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
flag = 'xxxxxxxxxxxxxxxxxxx'
s_box = 'qwertyuiopasdfghjkzxcvb123456#$'
tmp = ''
for i in flag:
tmp += str(bin(ord(i)))[2:].zfill(8)
b1 = int(tmp,2)
s = ''
while b1//31 != 0:
s += s_box[b1%31]
b1 = b1//31
print(s)
# s = u#k4ggia61egegzjuqz12jhfspfkay
审计注释:
1
2
3
4
5
6
7
ord ( i ): 返回字符 ` i ` 的 ASCII 码值。
bin ( ord ( i )) 将 ASCII 码值转换为二进制数。
str ( bin ( ord ( i ))) 将二进制数转换为字符串。
[ 2 :] 从第二个字符开始取,去除字符串开头的 '0b' 。
用 0 补齐字符串的左侧,使其总长度为 8 。
tmp += str ( bin ( ord ( i )))[ 2 :]. zfill ( 8 ) 将处理结果拼接到 tmp 中。
int ( tmp , 2 ) 将 tmp 解释为二进制数,并转换为整数类型。
本题考察取模逆运算
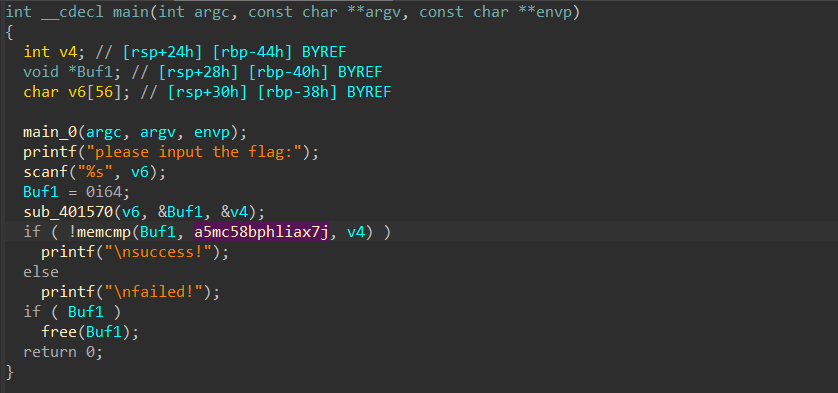
memcmp函数的原型为 int memcmp(const void *str1, const void *str2, size_t n);其功能是把存储区 str1 和存储区 str2 的前 n 个字节进行比较。该函数是按字节比较的,位于string.h。
如果返回值 < 0,则表示 str1 小于 str2。
如果返回值 > 0,则表示 str1 大于 str2。
如果返回值 = 0,则表示 str1 等于 str2。
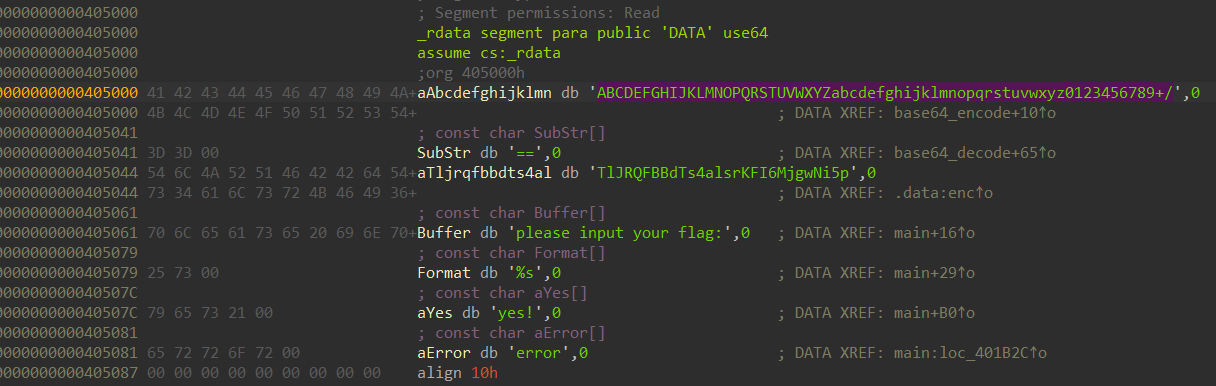
通过Shift+F12查看字符串,发现两段类似base64编码的字符串,猜测base64换表,脚本如下:
1
2
3
4
5
import base64
str1 = "5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8==" #str1是要解密的代码
string1 = "qvEJAfHmUYjBac+u8Ph5n9Od17FrICL/X0gVtM4Qk6T2z3wNSsyoebilxWKGZpRD" #string1是改过之后的base64表
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
python脚本:
1
2
3
4
5
6
from base64 import *
enc = "TlJRQFBBdTs4alsrKFI6MjgwNi5p"
str = b64decode(enc).decode()
for i in range(len(str)):
print(chr(i + ord(str[i])),end='')
NSSCTF{B@se64_HAHAHA}
一个xor加密
使用 npm 包 escodegen 解密
安装 escodegen
2.将json 文件转换成 js语句
1
2
3
4
5
6
7
8
9
10
$ esgenerate 附件 . json
( function () {
function bE ( str , key ) {
var arr = str . split ( '' );
return arr . map ( i => {
return String . fromCharCode ( i . charCodeAt () ^ key );
}) . join ( '' );
}
console . log ( bE ( 'EXXH_Mpjx \x7F BxYnjggrM~eerv' , 11 ));
}());
3.执行语句即可获得 flag
1
2
3
4
5
6
7
8
9
10
11
12
$ node
Welcome to Node . js v14 . 13.1 .
Type ".help" for more information .
> ( function () {
... function bE ( str , key ) {
..... var arr = str . split ( '' );
..... return arr . map ( i => {
....... return String . fromCharCode ( i . charCodeAt () ^ key );
....... }) . join ( '' );
..... }
... console . log ( bE ( 'EXXH_Mpjx \x7F BxYnjggrM~eerv' , 11 ));
... }());
NSSCTF{astIsReallyFunny}