Reverse-Basis1
reverse基础1
操作码(opcode)也就是机器指令
C语言编译流程:
|
|
0x01IDA定位main函数
打开字符串表,进行字符串搜索来定位,随后通过交叉引用列表定位到引用了该字符串的代码

定位之后对符号重新命名
strcmp用来进行字符串比较,若相同的话,返回0,若进行取反,即!strcmp则字符串相同返回1
0x02简单的加密算法
举一个简单的小栗子 根据加密逻辑进行一个逆运算

再来看一个简单的小栗子
异或
异或(xor)是一个数学运算符。它应用于逻辑运算。异或的数学符号为“⊕”,计算机符号为“xor”。
异或也叫半加运算,其运算法则相当于不带进位的二进制加法:
二进制下用1表示真,0表示假,则异或的运算法则为:0⊕0=0,1⊕0=1,0⊕1=1,1⊕1=0(同为0,异为1),
关键理解:不进位的二进制算法
明文^密钥=密文 密文^密钥=明文
拿到T3拉进IDA,按照之前所学,定位main函数,反编译之后修改函数名
|
|
进行代码审计,其加密操作为
|
|
根据异或运算原理,我们将密文再进行一次异或运算即可得到明文,从IDA中提取密文,使用LazyIDA进行数据提取
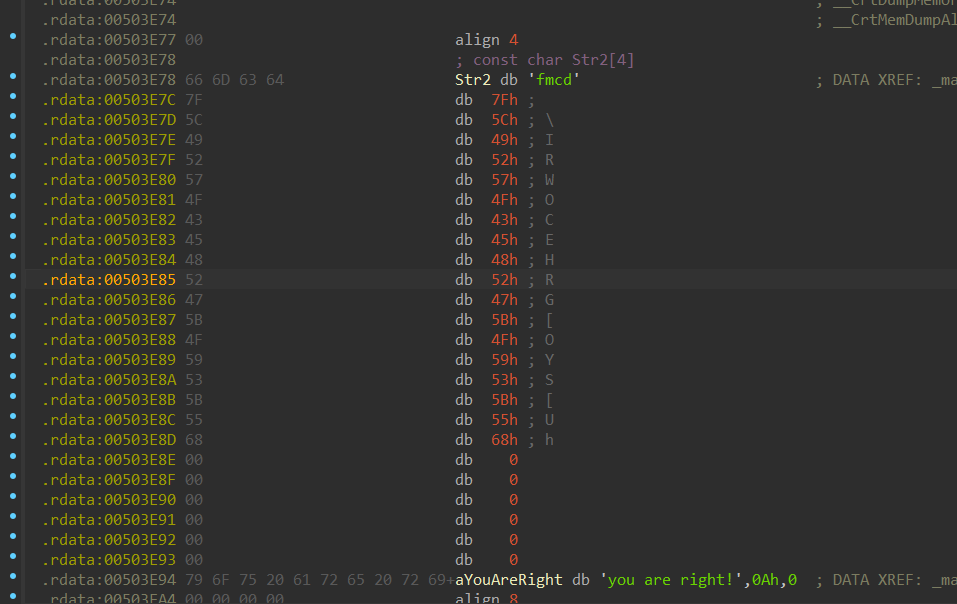
得到数据为(字节数组)
|
|
写一个python脚本进行异或操作
|
|
得到flag
当然,我们也可以根据修改后的IDA伪代码,编写C语言脚本来实现逆向计算
|
|
strlen()要加#include <string.h>函数头
总结一下,逆向,就是对代码执行流程进行正向分析,然后通过脚本进行逆向计算
0x03 Base64编码逆向
T4这道题大体思路跟前面的一样,无非是加了一个Base64编码的函数
主要代码如下:
|
|
我们猜测 sub_455A94(Str, Str1, v3);这个函数就是Base64编码的函数(可以双击进入查看代码)

当然,Base64编码原理并不影响我们解题,直接对主函数中给出的已进行Base64编码的字符串进行还原,得到v3的原始值,随后进行对如下代码的逆运算,即可得到flag
|
|
完整的c脚本
|
|
要注意的是,直接用ctf编码工具会将\x7f\智能(障)地转换成其他东西,导致下一步的逆向计算得到残缺的flag,为保证数据原汁原味,还是用python里的库进行手动转换吧
|
|
0x04 Base64变表逆向
跟上一栗子思路一样,无非是把base64标准算法表进行了魔改
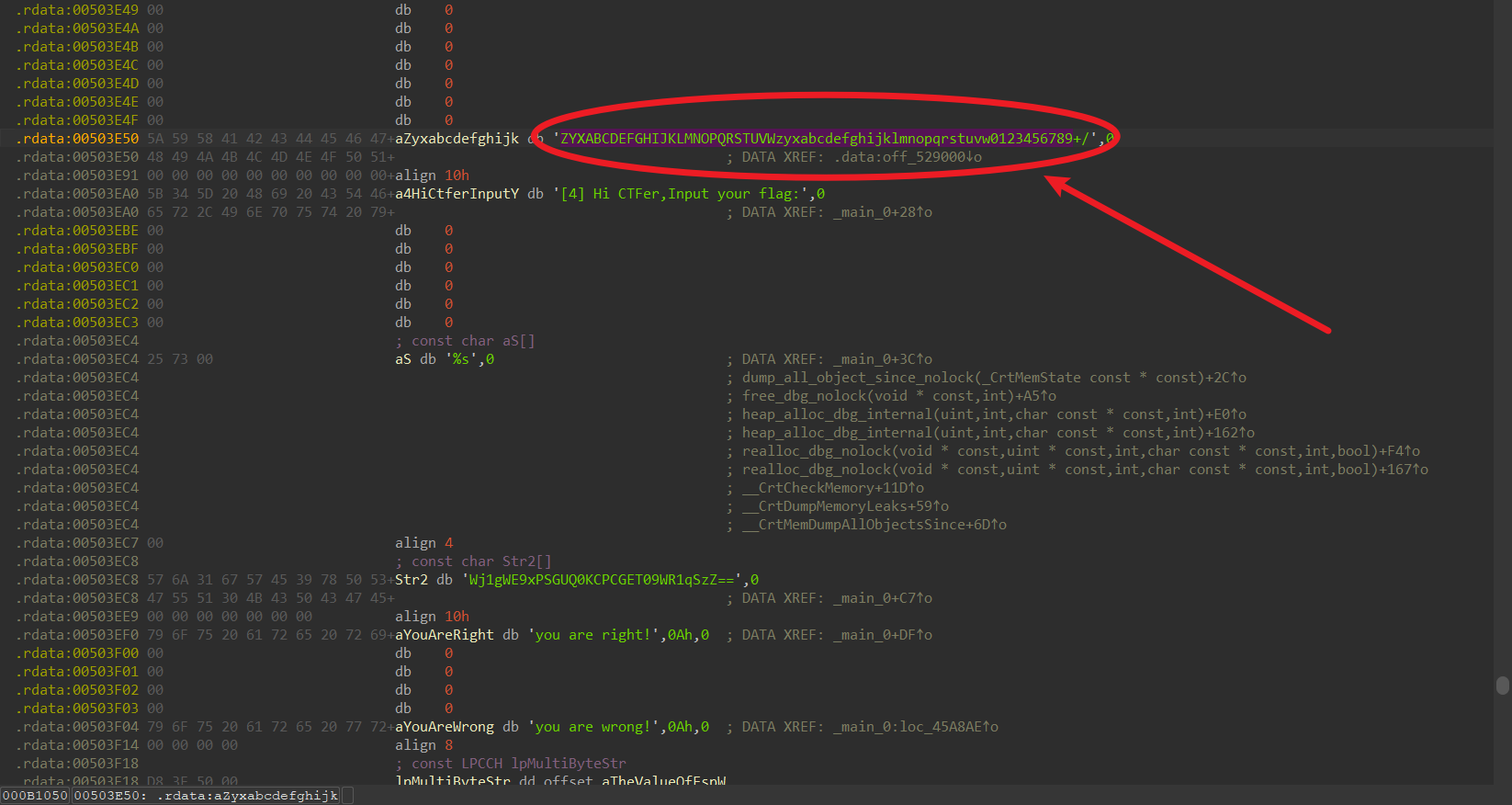

对程序里的base64加密过的字符串进行对等位置的替换,用手替换也行,写个脚本替换也行,下面是python脚本
|
|
对
result += T4[T5.index(ch)]说明
- 遍历字符串
data中的每个字符ch。- 使用
T5.index(ch)查找字符ch在字符映射表T5中的位置,返回它在T5中的索引。- 使用
T4[T5.index(ch)]找到T5中索引对应的字符在T4中的映射值。- 将
T4[T5.index(ch)]所对应的字符添加到result中。
要注意的是,data中的等于号(==)是用来补充位数的,在逆向魔改变换的时候未加入,所以在替换之后的result(标准编码表编码的base64)需要添加两个“=”才能进行标准base64表解码
0x5 IDA 动态调试
进行代码审计,可知程序将我们输入的str2与str1的值进行比对,
但str1是固定的,并不受输入影响,而且我们并不知道str1的具体数值
我们可以启用调试功能,当该程序运行到指定位置(通过strcmp函数对比str1和str2比对的位置)时,查看内存中str1的值
在此处代码前方打上断点(快捷键F2)进行调试,
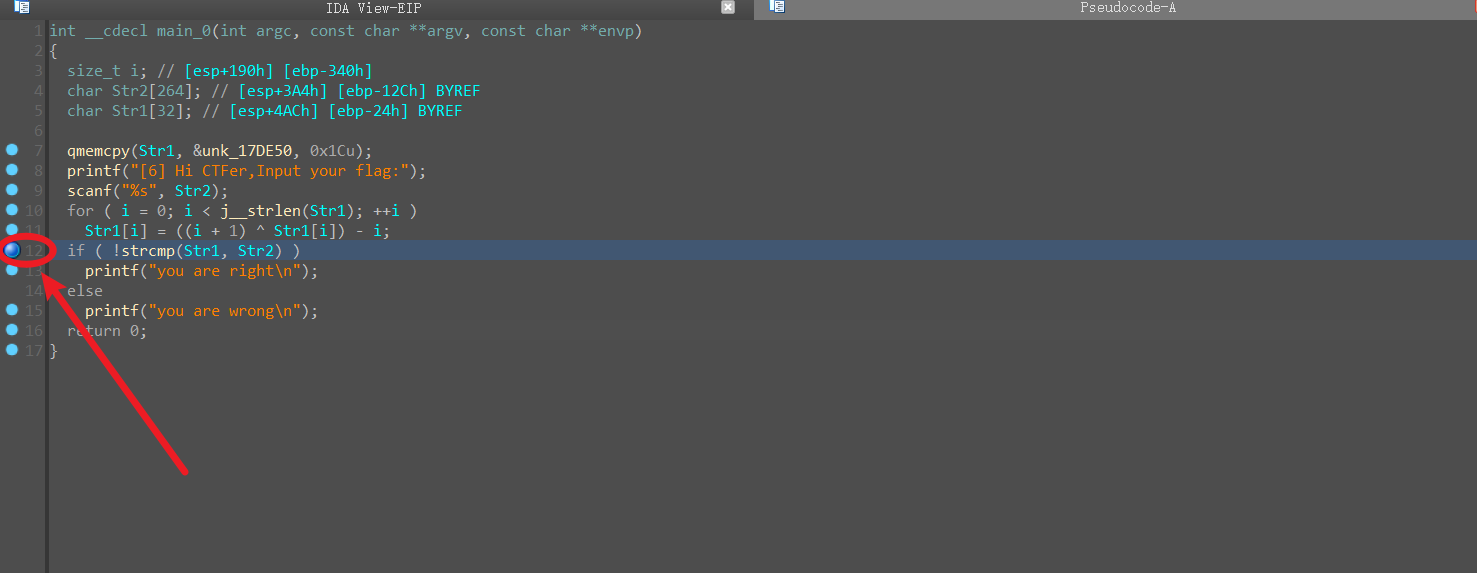
双击进入str1在内存地址中的起始位置,可看到str1的具体数据,这种连续的内存实际上是一个字符串,通过右键进行变换得到拼合起来的flag字符串


对程序中猜测的base64编码函数的真实性验证(动态调试):
可以在程序中任意输入,如123,得到程序反馈的值,再将其与标准base64编码得到的值进行比对,若相同,则该未知命名函数为base64编码函数
下面我们尝试通过动态调试解RC4加密的问题:
定位main函数,进行反编译,本次得到的原始代码与以往不同,复杂了很多
对以判断的函数名进行修改,当我们通过代码审计,没有显而易见的scanf函数,但当运行程序时,却需要我们输入内容,然而那个名为getchar的函数时做教程的师傅猜的(或许是基于经验)

数值10对应的ASCII码是\n,这里直接让其显示\n
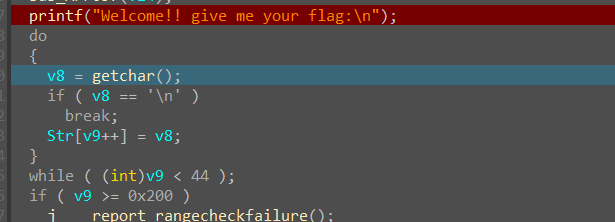
分析这段代码,可知其使用了一个 do-while 循环,从标准输入中读取字符将其赋值给v8,若读取到了换行字符,则跳出该循环语句,将 v8 存储在字符数组 Str 的下标为 v9 的位置上,并检查 v9 是否小于 44,如果是,则回到第 2 步继续读取字符。
|
|
那我们就输入一个长度为44的字符串
我们可以通过打断点的方式进行动态调试
在已经判断出的printf函数位置打一个断点,执行调试
然而,本程序有反调试机制,无法直接调试, 通过代码审计,推测反调试的代码位于printf上面,双击查看(反调试是后面的内容,这里不做展开学习)
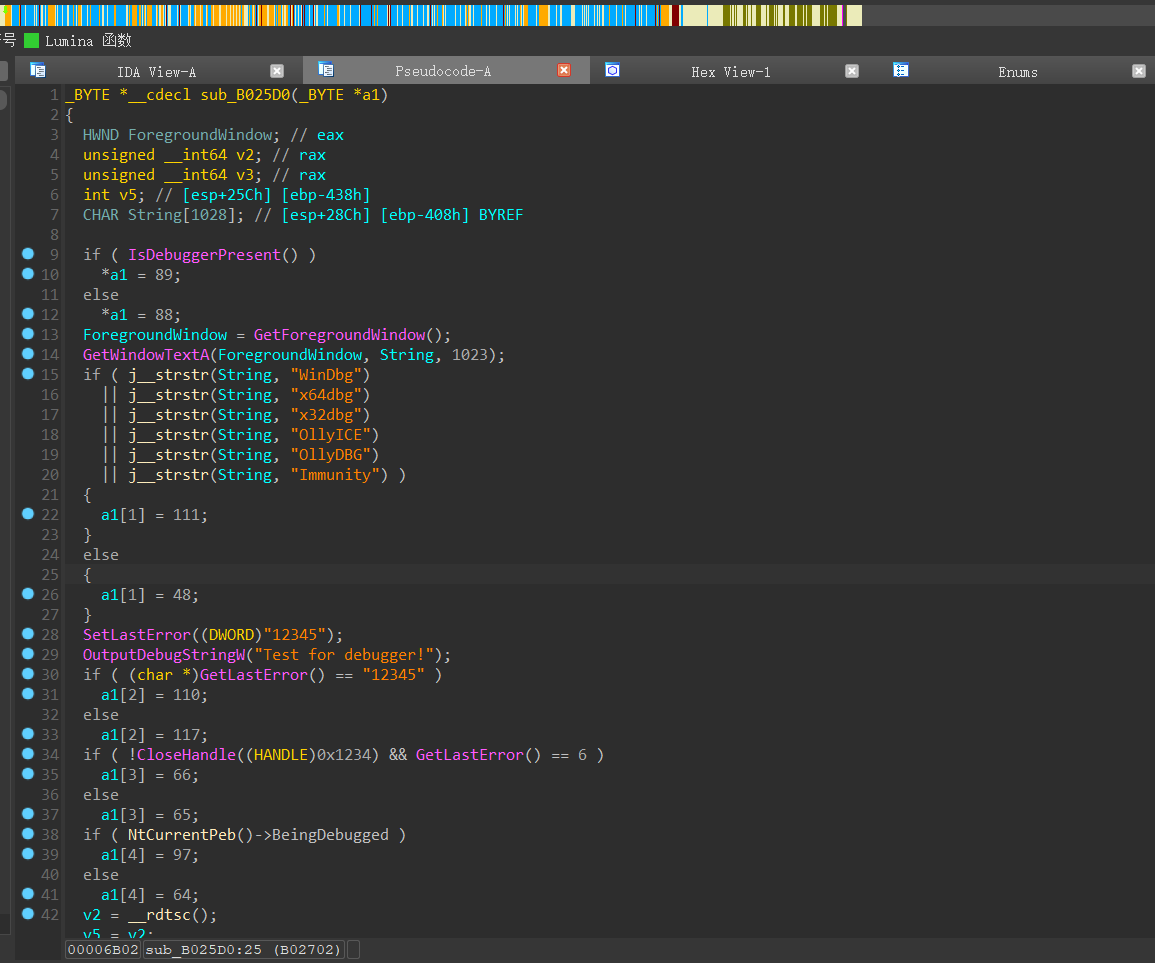
该反调试机制只运行一次,需要绕过反调试,我们首先运行该程,当程序输出以下内容时,说明反调试代码已经执行完

通过调试器的 ‘附加到进程’ 功能,调试一个正在运行的程序,找到相应程序

ok进入调试页面
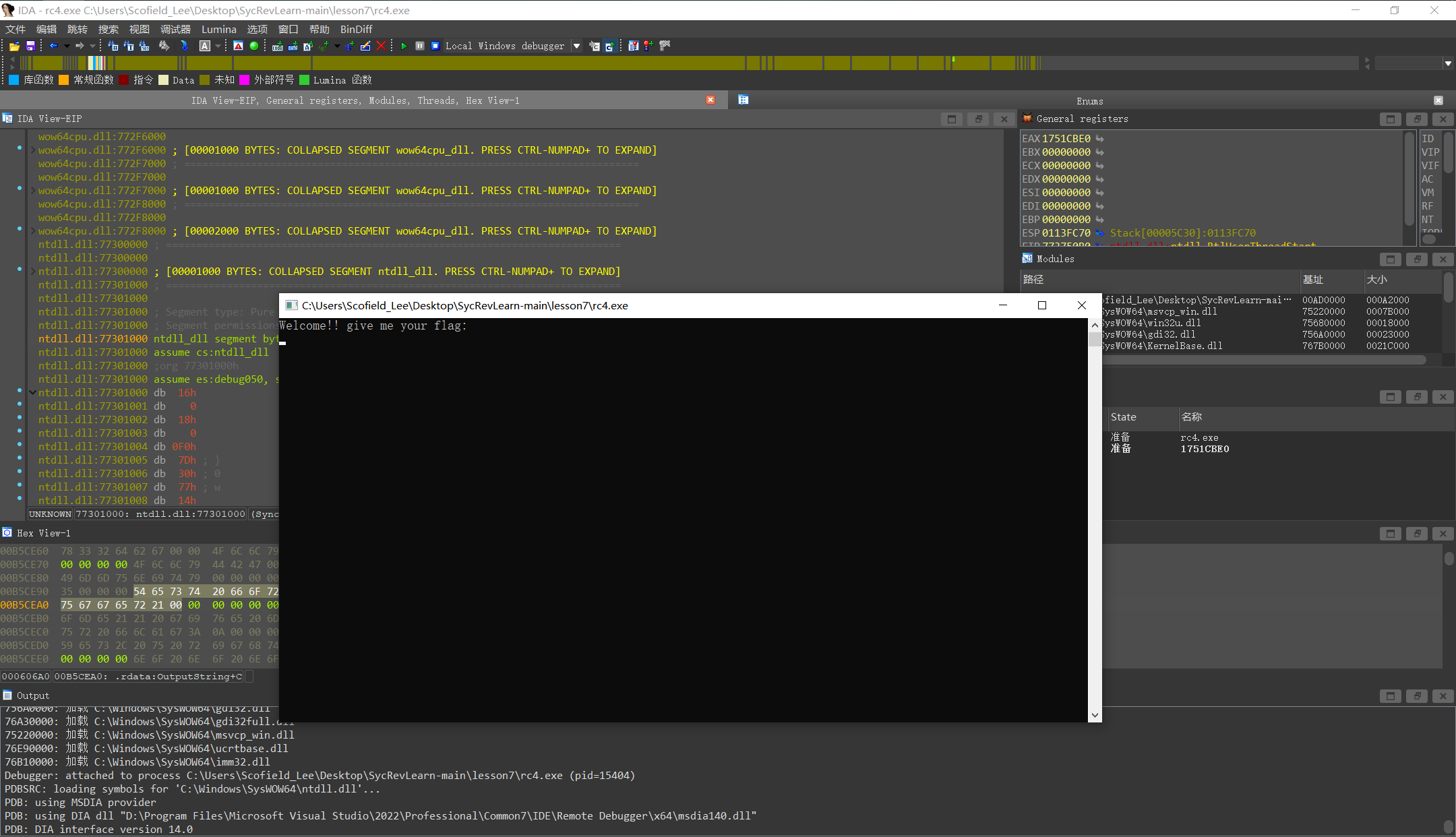
按F8单步执行,程序在我们打断点的位置停住了,输入内容后程序才能继续执行
传入一个长度为44的字符串
|
|
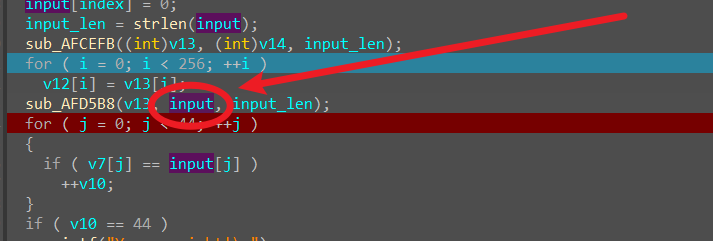
input为原来的Str,input_len为原来的v6
当我们传入44个A时,双击input变量,追踪其内存情况
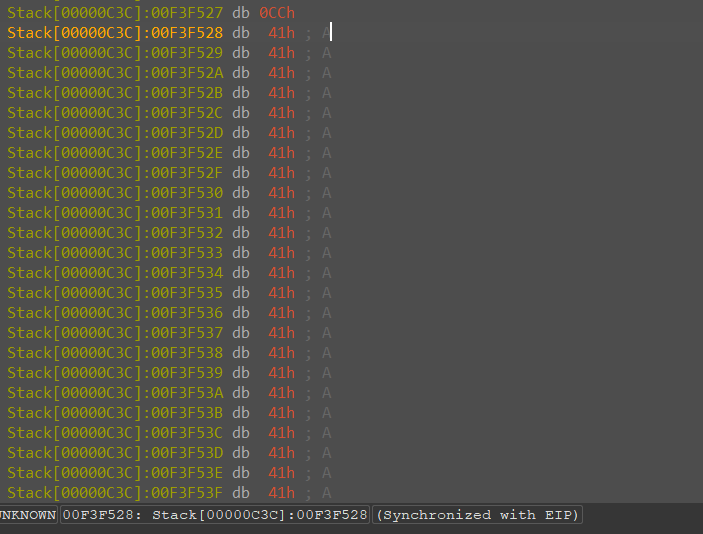
发现其为我们传入的44个A字符串,我们记录一下其首位地址内存00F3F528
传完44个A之后,程序进行跳出原本的for循环,进入下一步,逐一判断这44个字符与v7字符串组是否相同,若相同,则该44个A组成的字符串为flag(显然不是)

让程序运行到返回为止
按G键跳转到指定内存地址00F3F528,发现原本为连续字符串A的地址处,值发生变化
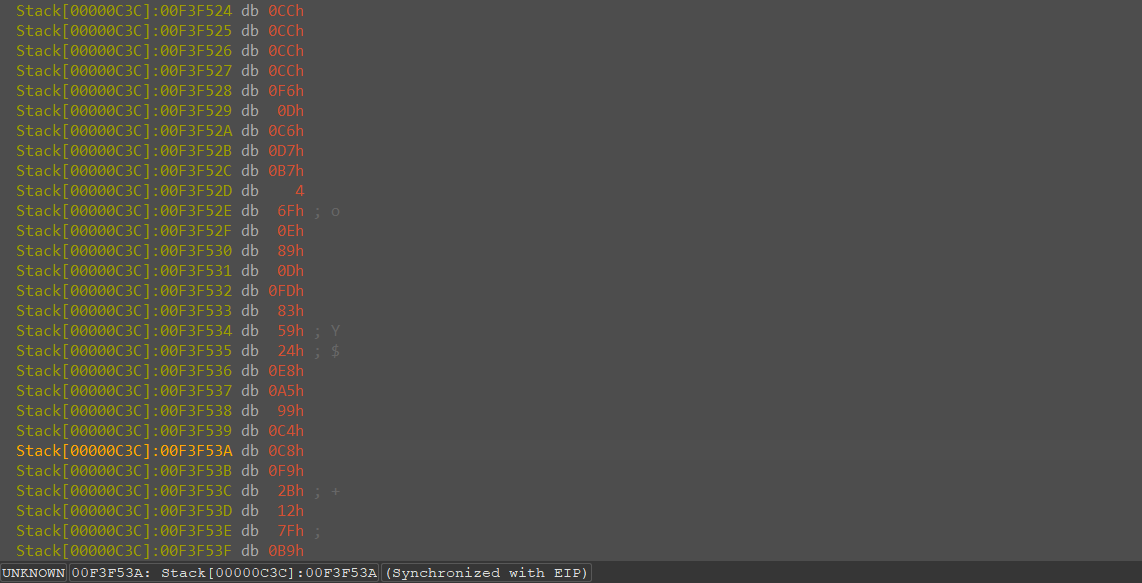
随后选取原本为A的这44个地址位置,将其转换为16进制字符,即为加密后的数据(本程序是有加密函数,因为其超出本节学习内容,故在前面分析的时候并没有提到),就是说,我们传入的44个A被程序加密成了下面这行字符串
|
|

这时,我们要求算法的逆向,就是通过上述加密后的字符串来得到44个A,要验证改程序的加密和解密是否是同一个过程,需要把上述加密后的数据重新输入到程序中进行加密操作,看能得到什么
我们重新运行程序,但由于加密后的字符中有些为不可见字符,我们不能直接通过输入上述加密后的字符串来进行验证
因此我们可以先输入其他字符(如44个1),先让其填满内存(此时程序已经运行),再通过修改内存来达到传入上述加密字符串的目的
|
|
在sub_AFD5B8函数位置打断点

此时追踪查看input的内存情况
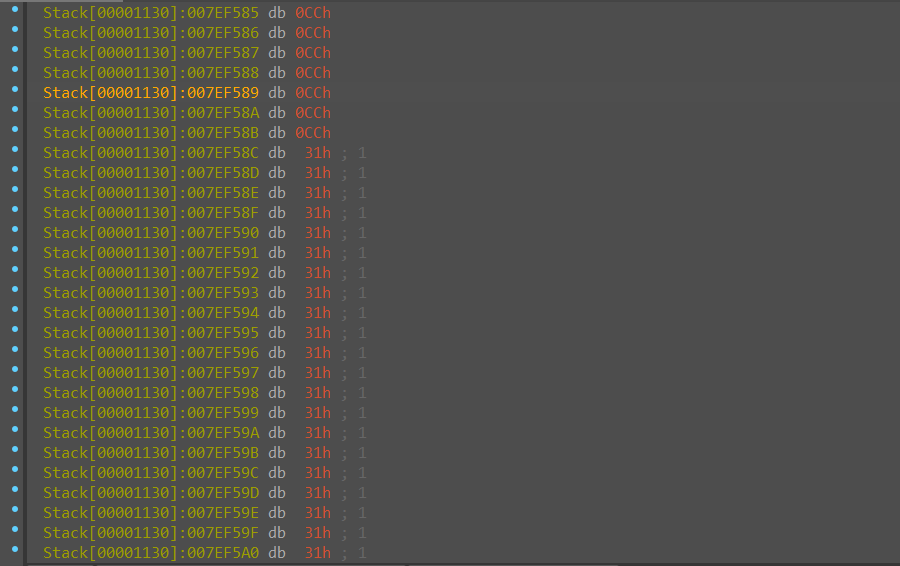
需要将内存中这些1修改为上述加密过的值,这里用到了一个修改插件(在修改版的LazyIDA中)地址如下
|
|


修改完成,记录首地址010FF6C4

然后进行单步运行,随后回来看刚才记录的首地址010FF6C4

发现其数据变成了该字符串加密前的44个A,
既然该程序的加密和解密是同一个过程,那想要得到flag,我们只需要将v7里面的数据(加密过的)传入到程序中,即可得到解密的v7数据,即得到flag
这样的话,我们直接追踪v7的内存,将其复制出v7的十六进制数据
|
|
得到了加密后的v7(flag的加密数据),我们以同样的方式,置换内存中已填入的44位可见字符数据(比如我们依然输入44个1)
然后追踪Str(后来被我们改成input的变量)内存地址,得到解密后的flag数据
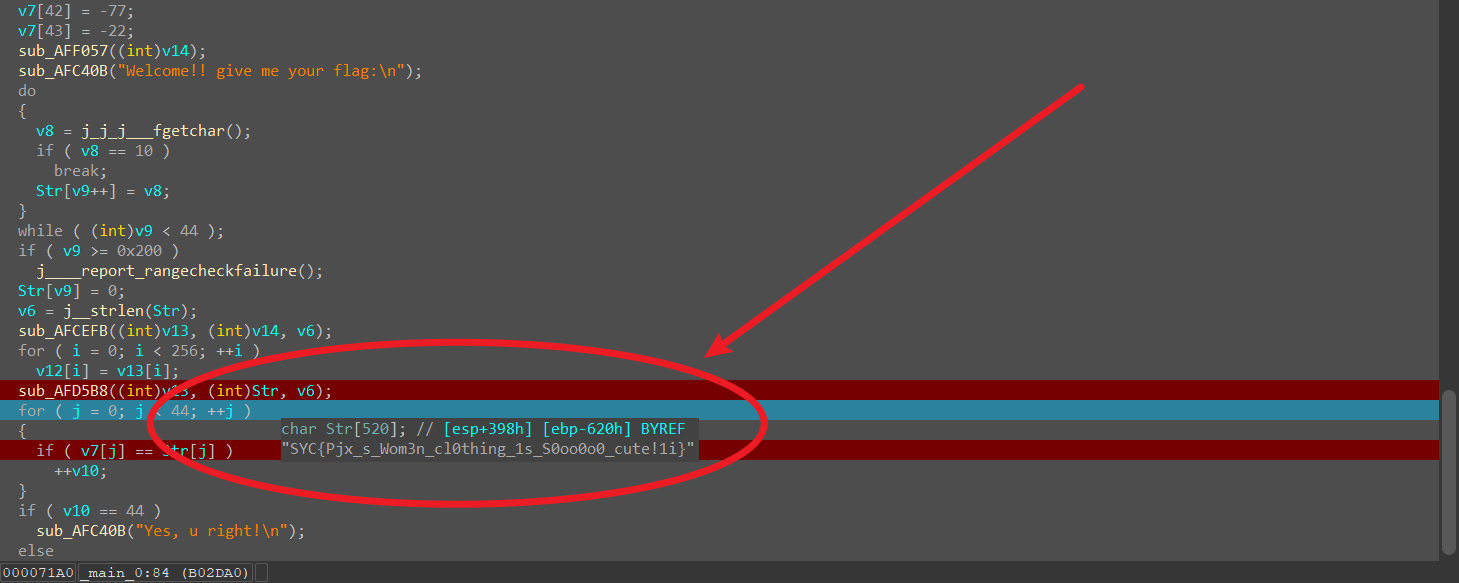
双击Str,并将连续的内存选中,转为字符串,即可得到易复制的flag字符串
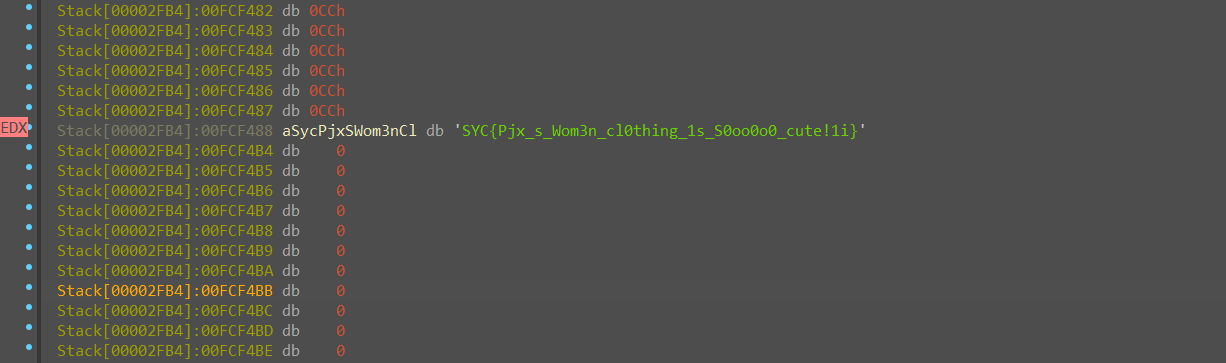
通过上述步骤,在不写脚本的情况下完成了对RC4加密算法的逆向解密
该逆向手法对其他流密码一样适用
0x6 IDA 代码修复入门
程序在编译阶段会丢失很多信息,把低级语言转为高级语言,由于信息补全,IDA会生成一些不合理的代码
strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回 str1字符串从 str2第一次出现的位置开始到 str1结尾的字符串;否则,返回NULL。
数组修复分为以下情况:
- 数组指针修复
- 数组数据修复
数组指针修复是指修正指向数组指针的类型,IDA可能将一些指针变量识别成整数变量
数组数据修复是指修复数组实际数据定义处的类型,数组实体可能存放在栈中,也可能存放在去全局数据段
(字符串也是数组)
这节课主打的是实战分析,没有太多新知识点
0x7 UPX脱壳处理
加壳,程序的一种保护机制,防止被逆向
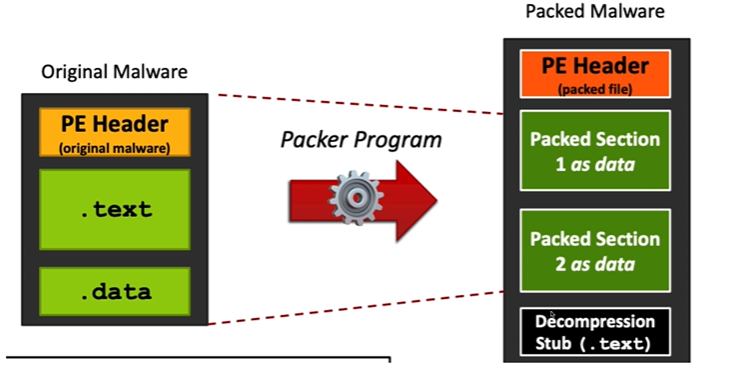
UPX是一种开源的压缩壳
https://github.com/upx/upx/releases
加壳可执行文件:upx.exe sample.exe 脱壳可执行文件:upx.exe -d sample.exe
手动脱壳的目标: 1.找到原始程序入口地址(OEP) 2.在原始程序入口地址处设置硬件断点(下次调试可快速进入原始代码,硬件断点不会修改数据)
进阶目标: 脱壳到文件,并修复运行
远程Linux动态调试
使用IDA文件夹里面的dbsrv/linux_server64,把这个文件传入Linux系统并运行(这里我用的是Ubuntu),回到IDA程序,在调试器里面选择远程Linux动态调试,输入远程Linux的IP地址和密码即可连接(端口号一般是默认的) 关于IDA远程Linux动态调试这里不做详细展开,可以百度看详细教程。
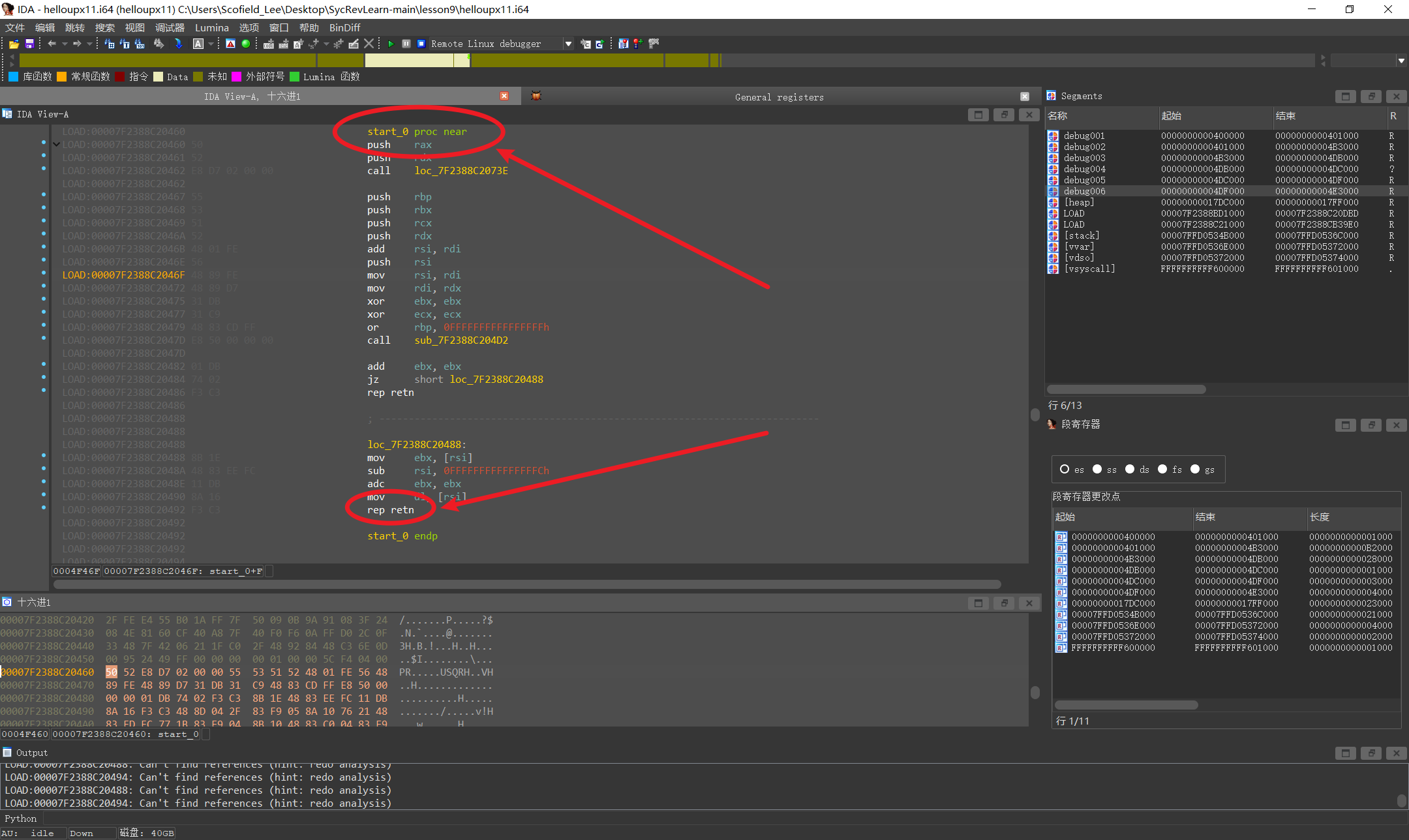
retn是一条返回指令,相当于C语言的return,按F4让程序执行到此位置
call指令进行函数调用
这里插一句,IDA的调试快捷键
使用f7 调试的时候遇到方法体的时候会进入到方法体内部 每个方法依次执行 使用f8 调试的时候 遇到方法体不会进入方法内部 只会依次执行 使用f9 调试的时候 只会执行 打断点的地方
OKAY,我们貌似找到了真正程序的入口

按F7跳转入该方法内部查看

进入某一块地址之后,IDA可能将代码识别生成数据,我们可以按C快捷键,将其转化为代码,随后按P创建函数,之后就可以按F5进行反编译随后就根据以往的流程进行逆向。