一点无处搁置的基础-2022.9
第一次CTF基础学习笔记
Hello,everyone!
I’m new in town!

HTTP基础
◎HTTP协议解析
HTT(HyperText Transfer Protoclo)即超文本传输协议,详细规定了浏览器和万维网服务器之间互相通信的规则,是万维网交换信息的基础。
◎HTTP请求
◎HTTP之url
在浏览器地址栏输入一个URL并按回车即可发起一个HTTP请求。
URL(统一资源定位符)也被称为网页地址 标准格式:协议://服务器IP[:端口]/路径/[?查询]
例如,https://www.qlu.edu.cn/wxxgk/list.htm ◎服务器域名:www.qlu.edu.cn ◎ 协议:https ◎http默认端口443 ◎路径wxxgk/list.htm
◎HTTP协议详解
HTTP协议目前的最新版本是1.1,HTTP是一种无状态的协议,所谓无状态是指Web浏览器与服务器之间不需要建立持久的连接,即当一个客户端向服务器端发出请求,然后Web服务器返回响应,连接就关闭了,在服务器端不保留连接的有关信息。
HTTP请求只能由客户端发起,服务器不能主动向客户Duang发送数据。
◎HTTP请求
http请求包含三部分:请求行(请求方法)、请求头(消息报头)、请求正文
下面是学长抓取的例子:
|
|
◎第一行是请求行:
|
|
由请求方法(POST),请求路径(/inc/postdata.php)和协议版本(HTTP/1.1)3部分组成。
◎第二行以下为请求头(也称为消息头),、请求头由客户端自行设定。请求头与请求正文之间有一个空行
Host:请求的Web服务器域名或者ip地址 USer-Agent:HTTP客户端运行的浏览器类型的详细信息,通过该信息,Web服务器可以判断出当前HTTP请求的客户端浏览器类型,即浏览器的标识 Accept:指定客户端能够接受的内容类型,内容类型的先后次序表示客户端接受的先后次序。 Cookie:HTTP请求发送时,就会把保存在该请求域名下的所有Cookie值一起发送给Web服务器。 Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
◎请求正文:
|
|
请求正文常出现在POST请求方法中
◎HTTP响应
HTTP响应也由三部分组成,响应行、响应头(消息报头)和响应正文(消息主题) 下面举一个栗子:
|
|
第一行为响应行,其中有HTTP版本,状态码(200)以及消息“OK”
第二行至末尾的空白行为响应头,由服务器向客户端发送 HTTP响应头中包含服务器再传递过程中,在响应行中不能完全显示的信息。 Location:控制浏览器重定向到哪个页面。 Server:服务器的banner信息。 Set-Cookie:服务器发送给客户端的Cookie设置信息。 Cache-Control:服务器控制浏览器是否要缓存网页。
消息报头之后为响应正文,是服务器向客户端发送的HTML数据
◎HTTP请求方法

HTTP 1.0定义了 GET、HEAD、POST HTTP 1.1新增方法:PUT、DELETE、CONNECT、OPTIONS、TRACE 目前共八种
◎请求方法中,GET和POST最为常见,两者的区别: 1.GET方法没有请求正文,而POST方法有请求正文 2.GET方法请求数据长度限制,而POST方法请求数据没有长度限制 3.GET方法会在浏览器中显示请求的数据;而POST方法不会在浏览器中显示请求的数据,因此更为安全
(1)GET 用于获取请求页面的指定信息
|
|
(2)HEAD
HEAD方法除了服务器不能在响应里返回消息主体外,其他都与GET方法相同 此方法常用来检测超文本链接的有效性、可访问性和最近的改变,本方法速度最快
(3)POST
POST方法与GET相似,最大的区别在GET方法没有请求内容,而POST方法是有请求内容的。POST请求最多
◎附:http状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作。 |
| 2** | 成功,操作被成功接收并处理。 |
| 3** | 重定向,需要进一步操作以完成请求。 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求。 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误。 |

robots文件
◎so,what is “robots” ?
robots文件是网站和搜索引擎之间的协议,也是搜索引擎爬虫爬行网站的第一个访问的文件,官方叫做爬虫协议或者是机器人协议,robots全程为“网络爬虫排除标准”(Robots Exclusion Protocol),我们所做的任何网站都可以通过robots协议告诉搜索引擎我们网站的哪些内容可以访问,哪些内容不能访问。
◎robots文件的作用
1.可以屏蔽网站内一些打不开的链接
2.可以屏蔽搜索引擎蜘蛛访问网站内重复的内容和页面
3.阻止搜索引擎访问网站的隐私性内容
4.阻止搜索引擎访问网站的后台内容
5.告诉搜索引擎哪些内容是需要被访问的
◎robots文件的重要性
网页中重复页面、内容或者错误页面都可以通过robots文件来屏蔽或阻止访问,否则搜索引擎蜘蛛就会认为该网站的价值较低,从而导致搜索引擎给网站的评价降低,会直接导致我们的网站排名下降。
网站克隆
前言
当离线时,拥有 一份镜像进行持续观察很有效。Wooyun 被封杀,但是现在网上还有很多 Wooyun 镜像站,来继续发挥 Wooyun 的余热。镜像网站不会复制动态内容,也不会复制网站的中间件,因此这并不是对所有渗透测试环境都适用。国光我个人一般都是用来 “盗取” 炫酷的 HTML5 网站(嘘~~~),有时候用它离线存储一些网站,总之挺实用的。
使用 wget 复制克隆网站
介绍
Kali linux 默认安装了 wget 工具,它简单使用,Pentest Box 中也集成了 wget 命令,只要在终端下敲几个命令,就可以下载整个网站的 HTML 文件。wget 不能复制服务器的程序页面,例如 PHP 脚本页面。
使用方法
终端下输入:
|
|
这样就会把百度的首页复制下来,就是这么简单粗暴。这里使用了一连串的参数,可以使用 man 命令来查看 wget 的手册:
|
|
wget 的主要参数如下:
|
|
复制网站时可能会发生错误,尤其是在复制动态脚本页面的时候,这是因为生成页面的大部分代码是由动态脚本创建的,大部分站点的应用程序是不能访问到的。
注:文件一旦被下载,切忌不可以让其他人浏览和重新发布站点,这会违反版权法。(当然功放演练的话,钓鱼攻击除外)
在Linux终端中进行wget操作是,保存下来的文件会保存在终端当前所在的目录
使用 HTTrack 复制克隆网站
介绍
HTTrack 是一款免费的离线浏览器工具,和 wget 克隆复制镜像差不多,从服务器抓取 HTML 文件、图片、以及其他 CSS 文件并存储到你的计算机上。Kali 2.0 起默认预装了 HTTrack。
使用方法
终端下输入:
|
|
如果没有安装这个工具的话,那就现场安装一下吧,只需要 2 个命令:
|
|
这里提示要输入项目名称、存放网站的路径(默认为 /root/website) 和要克隆的目标站,我们这里以「搜狗浏览器官网」为例 先自定义输入「test」 然后 按下「 回车」
|
|
然后默认路径 「回车」
输入想要克隆的网站
|
|
下面 HTTrack 提供了一些选项,我们一般选择第二本选项 Mirror Web Site(s) with Wizard(具有向导递归层级的镜像网站) 输入:2
「回车」「 回车」「 回车」 后面的一些基本设置 一般一直「回车」下去 直到网站开始克隆为止,HTTrack 就开始进行网站克隆了。
小结
个人认为:wget 操作简单方便,但是克隆效果不及 HTTrack,HTTrack 虽然比 wget 稍微繁琐了一点,但是在爬一个大型网站上面,完整性要优于 wget。 对了,最后再提醒一下:注意版权。
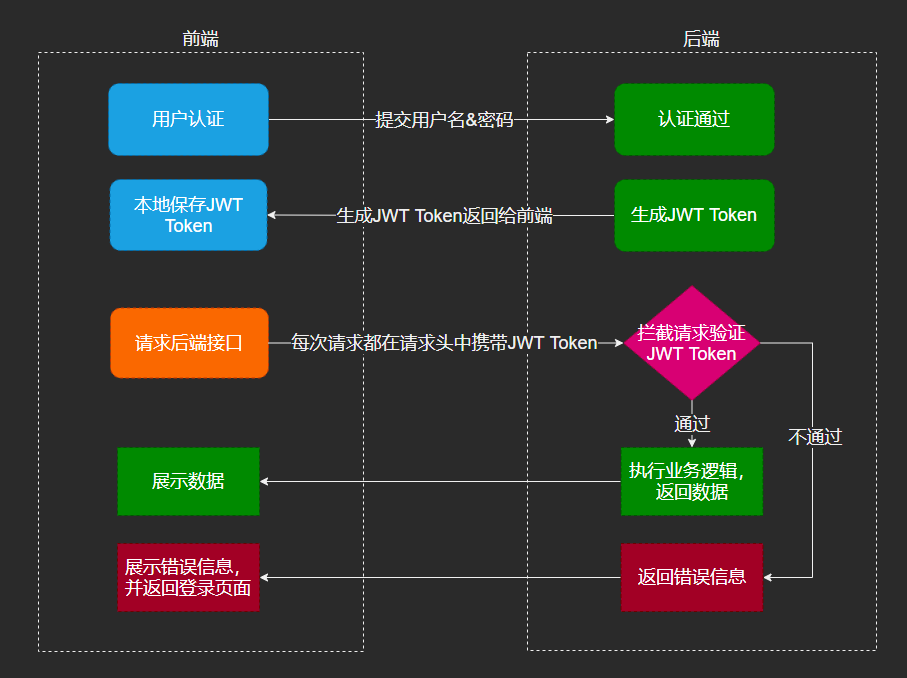
JWT基本概念
json web token(jwt) 是一个轻量级的认证规范,这个规范允许使用jwt在用户和服务器之间传递安全可靠的信息.其本质是一个token,是一种紧凑的url安全方法,用于在网络通信的双方之间传递.
我们可以进jwt官网看一下jwt.io

JWT漏洞
空加密算法
jwt支持空加密算法,可以在header中指定alg为none,这样的话,只要把signature设置为空,即不添加signature字段提交到服务器,任何token都可以通过服务器验证
但是我们会发现官网是没法生成空加密的,但是我们知道它的signature是base64,所以我们直接手工生成
|
|

|
|
(header+”.”+payload+”.”, 去掉了’.’signature字段)
空加密算法是为了调试方便,在生产环境中开启空加密模式,缺少签名保护,攻击者只要把alg字段改成none,就可以在payload中构造身份,伪造用户身份。
密钥爆破
我们可以使用c-jwt-cracker-master进行jwt密钥爆破
私钥泄露攻击
这里访问/private.key就能任意文件下载私钥,但是我们尝试在官网是无法生成的,但是我们可以自己写脚本生成
这里就需要在本地安装node,然后npm install jsonwebtoken
|
|
然后写这么个脚本,生成
公钥泄露攻击
jwt中最常用的两种算法为HMAC和RSA
HMAC是一种对称加密算法,使用相同的密钥进行加解密
RSA是一种非对称加密算法,使用私钥加密,公钥解密
在HMAC和RSA中,都使用私钥对signature字段进行签名,只有拿到了加密时使用的私钥,才有可能伪造token
密钥一般情况下是无法获取的,但是可以获取到公钥,我们可以将加密算法RSA改成HAMC,即将alg字段由RS256改成HS256,同时使用获取到的公钥作为算法的密钥,对token进行签名提交给服务端.服务器会将RSA的公钥作为当前算法(HMAC)的密钥,HMAC公钥和密钥相同,使用HS256算法会对接收到的签名进行验证。
|
|
但是这里要注意,我们在进行密钥攻击时,一定要用post方式
于2022年的SkyNICO三校联赛中,babytoken一题便是一道关于jwt破解题目,由于当时脚本没跑通,并未成功解题(超级遗憾,思路正确,脚本成了绊脚石)。可能是python更新换代的缘故,GitHub上搜到的Python脚本始终没有跑通的,赛后在charmersix师傅的指点下,通过编译c语言版的jwtcrack脚本,成功解题。 附c语言版jwtcrack脚本链接(要先编译):https://github.com/brendan-rius/c-jwt-cracker
认识漏洞
0x1什么是漏洞?
本质上是对现有信息资产的非预期使用,用户通过技术手段访问或者修改到不应该访问到的数据,执行不应执行的代码。
0x2漏洞产生的原因:
设计缺陷、逻辑错误,代码bug、越权漏洞、其他漏洞
0x3漏洞的利用方式

危害程度:

0x4 web题目的做题思路
读取flag信息
(判断漏洞类型)
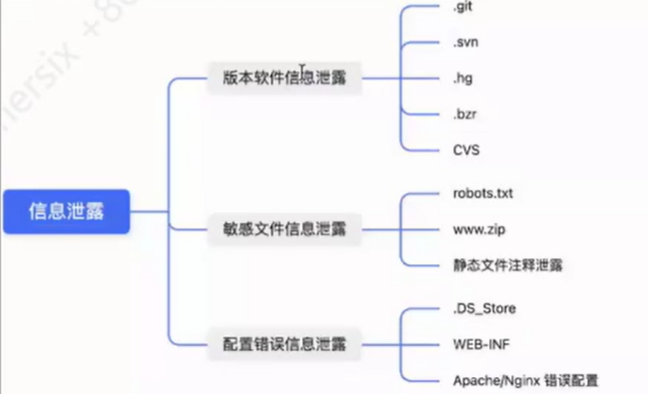
0x6信息泄露漏洞利用
1.http头信息泄露
/admin/表示访问的是admin目录,会默认访问目录里面的索引文件,比如index.html或者index.php
/admin表示访问admin文件,如果没有这个文件,就直接返回404,不回去寻找索引文件
(有时候加不加斜杠都能访问到/admin/,是因为配置文件里面进行了相关的设置)
/user表示访问的是user路由,而不是访问user这个文件,与要根据server头来判断,比如php、asp、html等,这些都是基于文件的。而那些看起来没有后缀的,则是基于路由的,需要多次判断。
2.报错信息泄露
报错信息泄露服务器状态
3.页面信息泄露
通过查看网站源码可查看到页面上不显示的信息
4.robots.txt敏感文件泄露
防君子不防小人 此地无银三百两
例如,百度的部分robots.txt内容:
|
|
有些网站不会有robots.txt这个文件,网站的robots文件内容不一定是真的,也有可能以此来钓鱼
5.git文件泄露
git是开源的分布式版本控制系统,可以解决多个开发不能并行开发,只能串联开发的问题 浏览瞎猜.git目录里面的文件,分析它的提交过程。
0x7Burpsuite与爆破
(没时间补笔记了,一下内容来自charmersix.icu)
抓包,爆破
bp的安装,Java环境,proxy插件
设置好代理,开启拦截,刷新一下你的浏览器就可以看见抓到的包
这里我们以bugku的一个题目为例子,演示一下使用bp进行爆破
现在我们打开题目,开启拦截
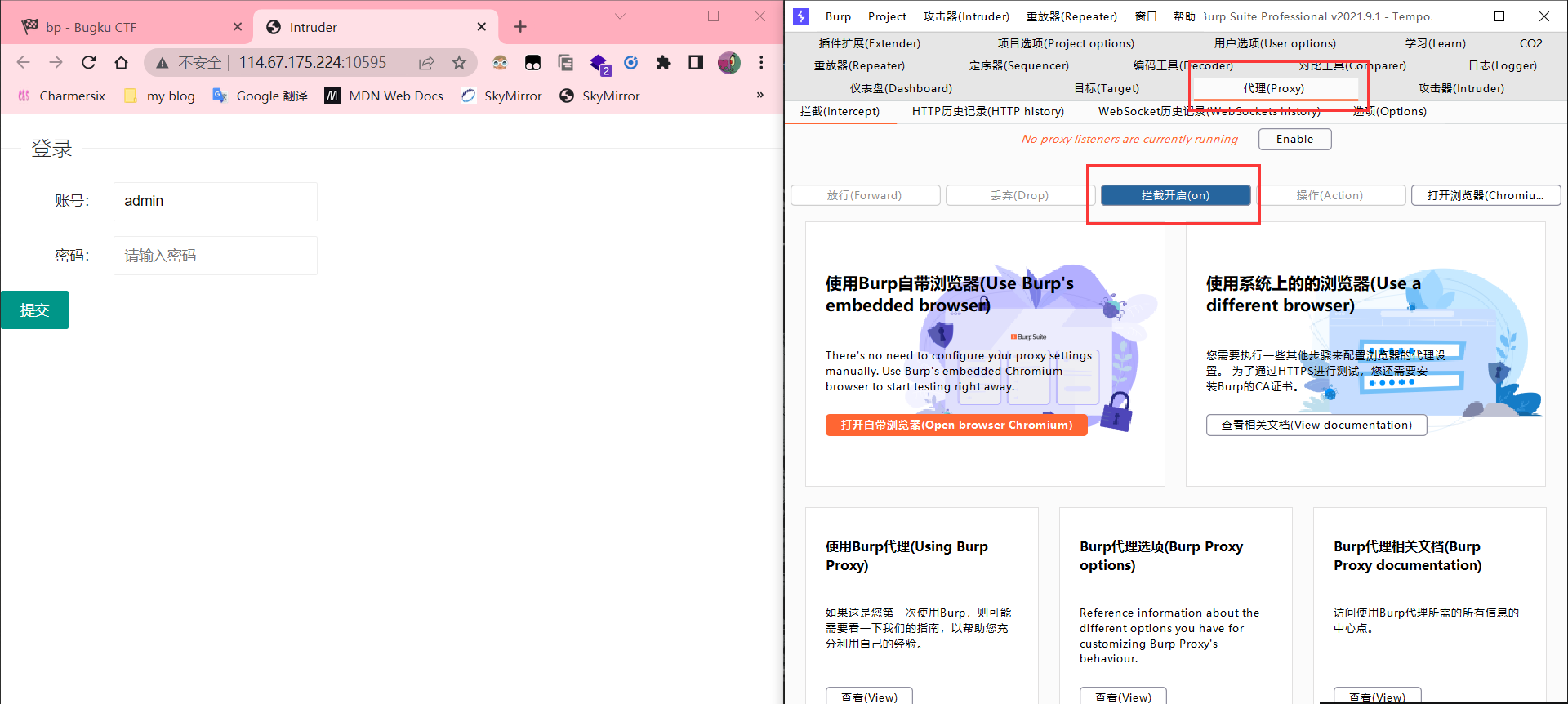
然后我们往里填一个自己猜的密码,比如我这里是123456
点提交,就能看见自己抓的包
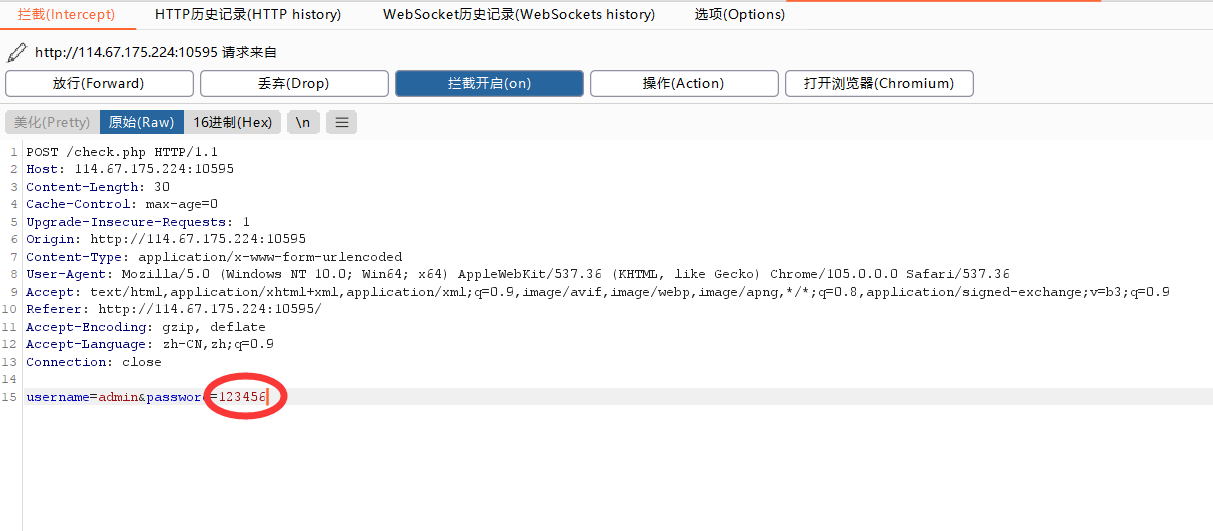
这里可以看见我们已经抓到了,我们点鼠标右键,发送到intruder
来到位置这里,我们可以把admin位置删掉,因为一开始admin给出了,不需要我们爆破
只需要删除admin两边的§符号即可
我们继续看下一栏
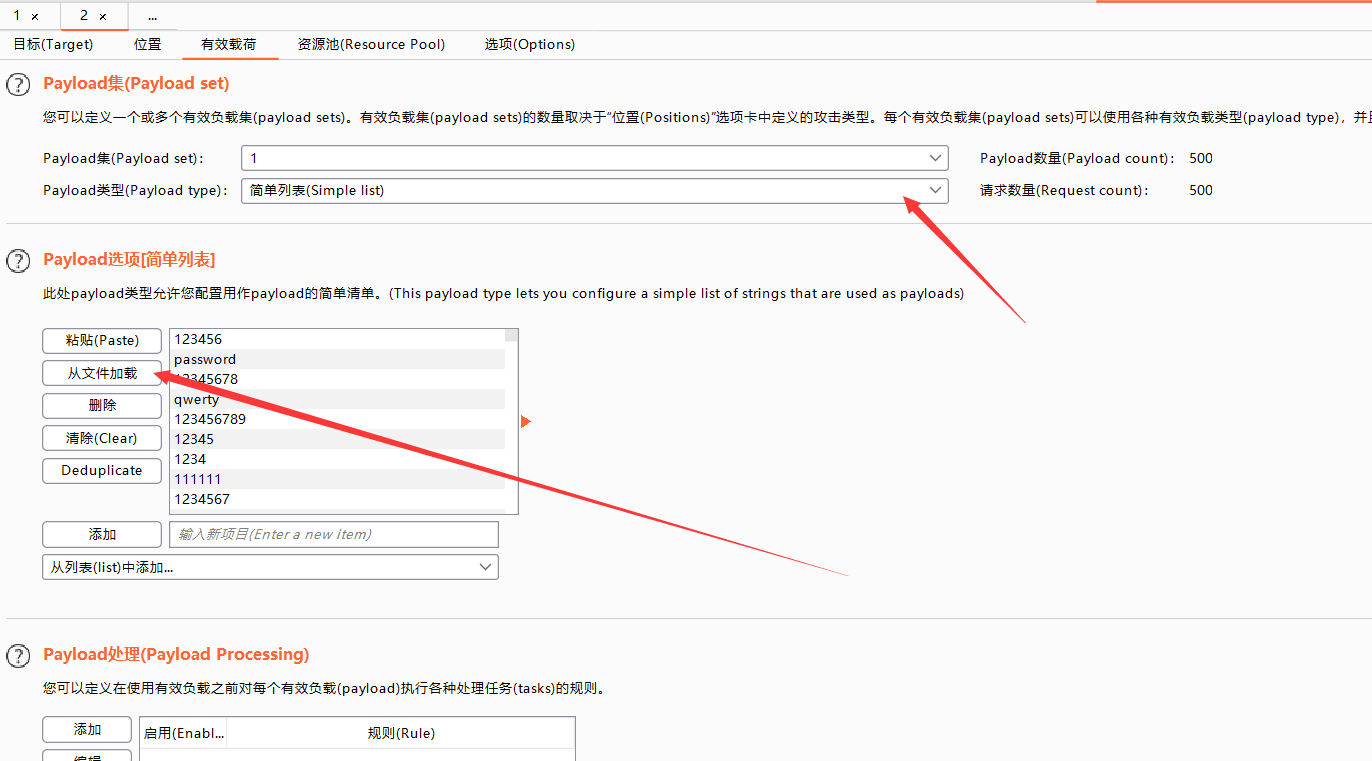
这里选择简单列表即可,然后导入我们从网上下载的top1000密码,开始爆破
失败
通过观察相应包,我们发现,无论是否爆破成功,这里都会通过js告诉你爆破失败
那我么只需要过滤掉{code: 'bugku10000'}就能知道,到底哪个是真正被爆破成功的
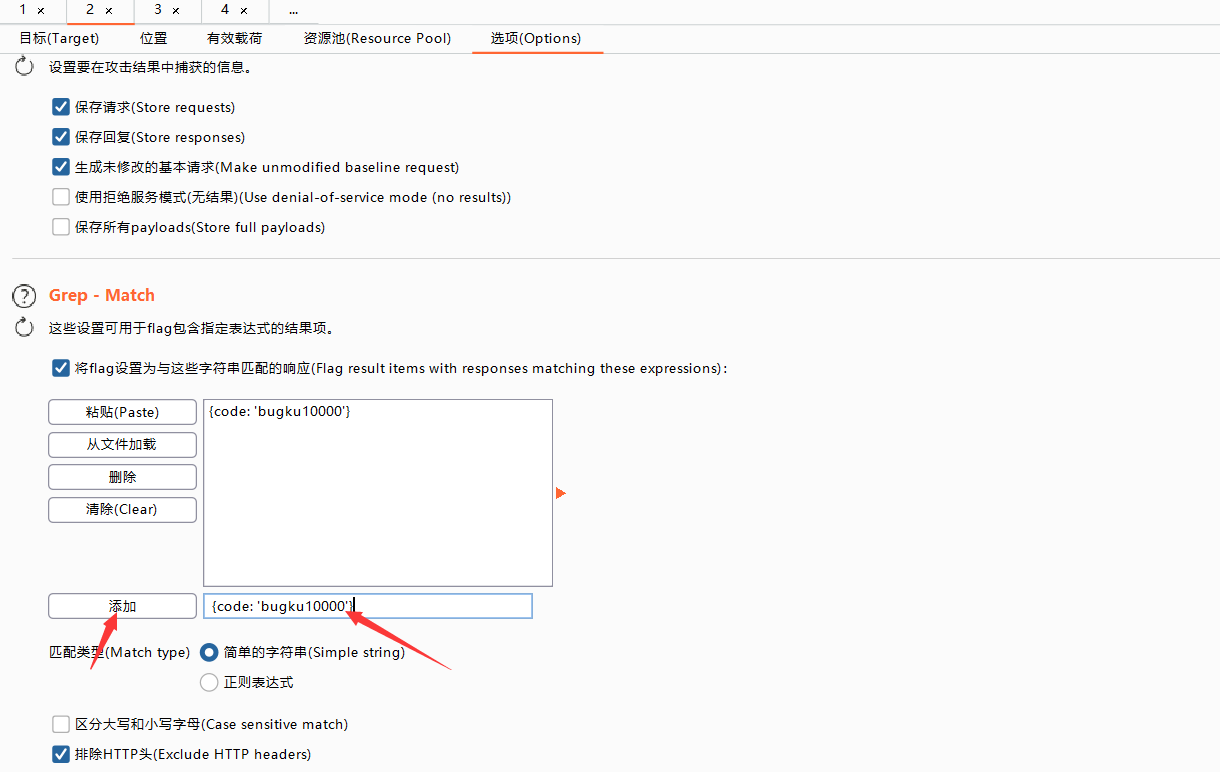
然后爆破,就能出密码